Track notebooks, scripts & functions¶
For tracking pipelines, see: Pipelines – workflow managers.
# pip install 'lamindb[jupyter]'
!lamin init --storage ./test-track
Show code cell output
→ initialized lamindb: testuser1/test-track
Track a notebook or script¶
Call track() to register your notebook or script as a transform and start capturing inputs & outputs of a run.
import lamindb as ln
ln.track() # initiate a tracked notebook/script run
# your code automatically tracks inputs & outputs
ln.finish() # mark run as finished, save execution report, source code & environment
Here is how a notebook with run report looks on the hub.
Explore it here.
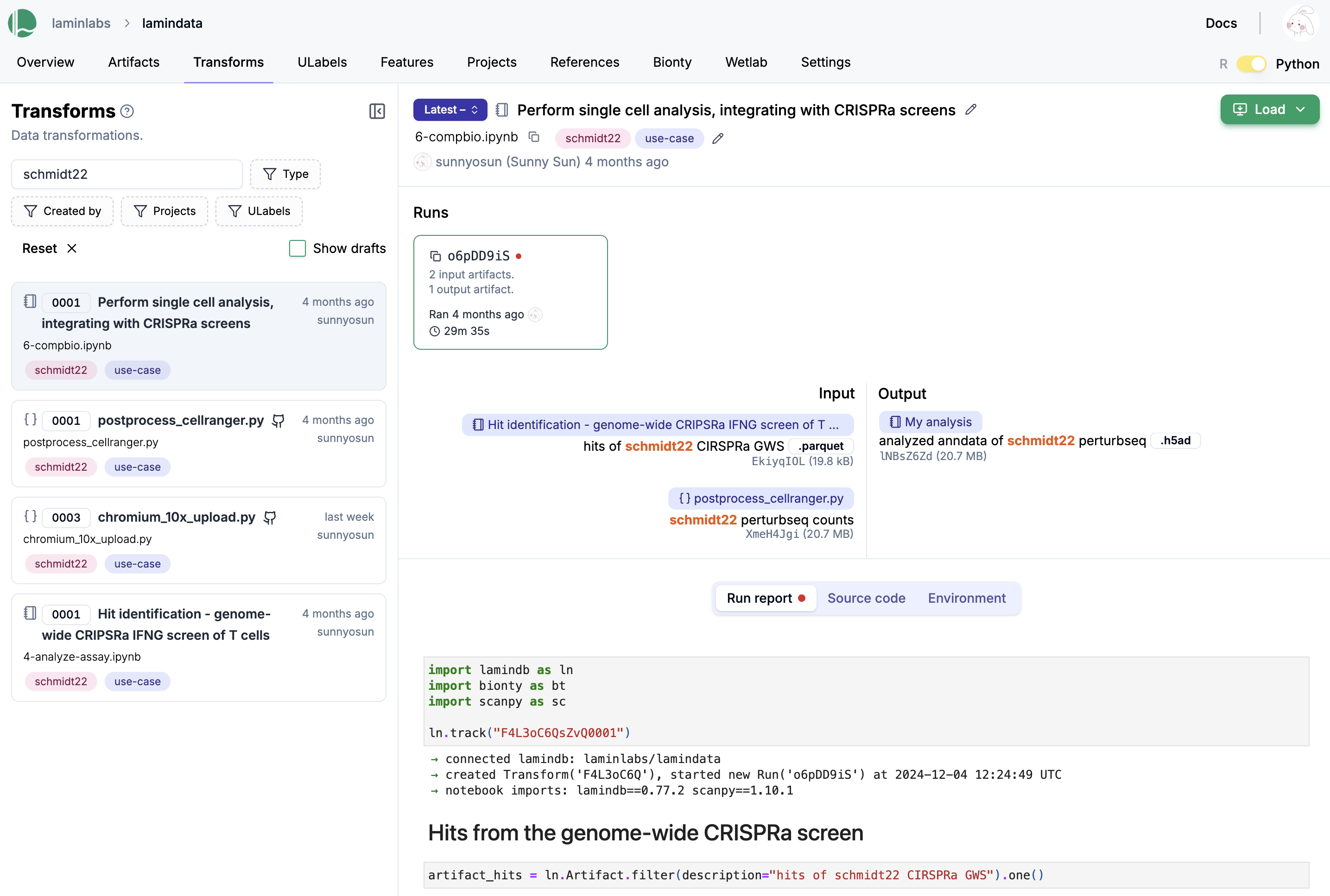
You find your notebooks and scripts in the Transform registry (along with pipelines & functions). Run stores executions.
You can use all usual ways of querying to obtain one or multiple transform records, e.g.:
transform = ln.Transform.get(key="my_analyses/my_notebook.ipynb")
transform.source_code # source code
transform.runs # all runs
transform.latest_run.report # report of latest run
transform.latest_run.environment # environment of latest run
To load a notebook or script from the hub, search or filter the transform page and use the CLI.
lamin load https://lamin.ai/laminlabs/lamindata/transform/13VINnFk89PE
Use projects¶
You can link the entities created during a run to a project.
import lamindb as ln
my_project = ln.Project(name="My project").save() # create a project
ln.track(project="My project") # auto-link entities to "My project"
ln.Artifact(ln.core.datasets.file_fcs(), key="my_file.fcs").save() # save an artifact
Show code cell output
→ connected lamindb: testuser1/test-track
→ created Transform('d3LEY4x5ZnlF0000'), started new Run('yuDyaffW...') at 2025-06-12 17:22:09 UTC
→ notebook imports: lamindb==1.6.2
• recommendation: to identify the notebook across renames, pass the uid: ln.track("d3LEY4x5ZnlF", project="My project")
Artifact(uid='gPAQMHTfl9M4T4sW0000', is_latest=True, key='my_file.fcs', suffix='.fcs', size=19330507, hash='rCPvmZB19xs4zHZ7p_-Wrg', branch_id=1, space_id=1, storage_id=1, run_id=1, created_by_id=1, created_at=2025-06-12 17:22:12 UTC)
Filter entities by project, e.g., artifacts:
ln.Artifact.filter(projects=my_project).df()
Show code cell output
| uid | key | description | suffix | kind | otype | size | hash | n_files | n_observations | _hash_type | _key_is_virtual | _overwrite_versions | space_id | storage_id | schema_id | version | is_latest | run_id | created_at | created_by_id | _aux | branch_id | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| id | |||||||||||||||||||||||
| 1 | gPAQMHTfl9M4T4sW0000 | my_file.fcs | None | .fcs | None | None | 19330507 | rCPvmZB19xs4zHZ7p_-Wrg | None | None | md5 | True | False | 1 | 1 | None | None | True | 1 | 2025-06-12 17:22:12.198000+00:00 | 1 | None | 1 |
Access entities linked to a project.
display(my_project.artifacts.df())
display(my_project.transforms.df())
display(my_project.runs.df())
Show code cell output
| uid | key | description | suffix | kind | otype | size | hash | n_files | n_observations | _hash_type | _key_is_virtual | _overwrite_versions | space_id | storage_id | schema_id | version | is_latest | run_id | created_at | created_by_id | _aux | branch_id | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| id | |||||||||||||||||||||||
| 1 | gPAQMHTfl9M4T4sW0000 | my_file.fcs | None | .fcs | None | None | 19330507 | rCPvmZB19xs4zHZ7p_-Wrg | None | None | md5 | True | False | 1 | 1 | None | None | True | 1 | 2025-06-12 17:22:12.198000+00:00 | 1 | None | 1 |
| uid | key | description | type | source_code | hash | reference | reference_type | space_id | _template_id | version | is_latest | created_at | created_by_id | _aux | branch_id | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| id | ||||||||||||||||
| 1 | d3LEY4x5ZnlF0000 | track.ipynb | Track notebooks, scripts & functions | notebook | None | None | None | None | 1 | None | None | True | 2025-06-12 17:22:09.699000+00:00 | 1 | None | 1 |
| uid | name | started_at | finished_at | reference | reference_type | _is_consecutive | _status_code | space_id | transform_id | report_id | _logfile_id | environment_id | initiated_by_run_id | created_at | created_by_id | _aux | branch_id | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| id | ||||||||||||||||||
| 1 | yuDyaffWo5cC9y3t | None | 2025-06-12 17:22:09.711478+00:00 | None | None | None | None | 0 | 1 | 1 | None | None | None | None | 2025-06-12 17:22:09.712000+00:00 | 1 | None | 1 |
Use spaces¶
You can write the entities created during a run into a space that you configure on LaminHub. This is particularly useful if you want to restrict access to a space. Note that this doesn’t affect bionty entities who should typically be commonly accessible.
ln.track(space="Our team space")
Track parameters¶
In addition to tracking source code, run reports & environments, you can track run parameters.
Track run parameters¶
First, define valid parameters, e.g.:
ln.Feature(name="input_dir", dtype=str).save()
ln.Feature(name="learning_rate", dtype=float).save()
ln.Feature(name="preprocess_params", dtype="dict").save()
Show code cell output
Feature(uid='O9lX1wOZa7Ng', name='preprocess_params', dtype='dict', array_rank=0, array_size=0, branch_id=1, space_id=1, created_by_id=1, run_id=1, created_at=2025-06-12 17:22:12 UTC)
If you hadn’t defined these parameters, you’d get a ValidationError in the following script.
import argparse
import lamindb as ln
if __name__ == "__main__":
p = argparse.ArgumentParser()
p.add_argument("--input-dir", type=str)
p.add_argument("--downsample", action="store_true")
p.add_argument("--learning-rate", type=float)
args = p.parse_args()
params = {
"input_dir": args.input_dir,
"learning_rate": args.learning_rate,
"preprocess_params": {
"downsample": args.downsample, # nested parameter names & values in dictionaries are not validated
"normalization": "the_good_one",
},
}
ln.track(params=params)
# your code
ln.finish()
Run the script.
!python scripts/run_track_with_params.py --input-dir ./mydataset --learning-rate 0.01 --downsample
Show code cell output
→ connected lamindb: testuser1/test-track
→ created Transform('YFQL4ZZuRI6R0000'), started new Run('iTteMw5u...') at 2025-06-12 17:22:15 UTC
→ params: input_dir=./mydataset, learning_rate=0.01, preprocess_params={'downsample': True, 'normalization': 'the_good_one'}
• recommendation: to identify the script across renames, pass the uid: ln.track("YFQL4ZZuRI6R", params={...})
→ finished Run('iTteMw5u') after 1s at 2025-06-12 17:22:16 UTC
Query by run parameters¶
Query for all runs that match a certain parameters:
ln.Run.filter(
learning_rate=0.01, input_dir="./mydataset", preprocess_params__downsample=True
).df()
Show code cell output
| uid | name | started_at | finished_at | reference | reference_type | _is_consecutive | _status_code | space_id | transform_id | report_id | _logfile_id | environment_id | initiated_by_run_id | created_at | created_by_id | _aux | branch_id | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| id | ||||||||||||||||||
| 2 | iTteMw5u6iMX8PVz | None | 2025-06-12 17:22:15.173342+00:00 | 2025-06-12 17:22:16.920746+00:00 | None | None | True | 0 | 1 | 2 | 3 | None | 2 | None | 2025-06-12 17:22:15.174000+00:00 | 1 | None | 1 |
Note that:
preprocess_params__downsample=Truetraverses the dictionarypreprocess_paramsto find the key"downsample"and match it toTruenested keys like
"downsample"in a dictionary do not appear inFeatureand hence, do not get validated
Access parameters of a run¶
Below is how you get the parameter values that were used for a given run.
run = ln.Run.filter(learning_rate=0.01).order_by("-started_at").first()
run.features.get_values()
Show code cell output
{'input_dir': './mydataset',
'learning_rate': 0.01,
'preprocess_params': {'downsample': True, 'normalization': 'the_good_one'}}
Here is how it looks on the hub.
Explore parameter values¶
If you want to query all parameter values together with other feature values, use FeatureValue.
ln.models.FeatureValue.df(include=["feature__name", "created_by__handle"])
Show code cell output
| value | hash | feature__name | created_by__handle | |
|---|---|---|---|---|
| id | ||||
| 1 | ./mydataset | 71I4KdtOlqWZYoR9KaVTvw | input_dir | testuser1 |
| 2 | 0.01 | BIF-_RHBU2Sm7COXgAOIYg | learning_rate | testuser1 |
| 3 | {'downsample': True, 'normalization': 'the_goo... | 4ehQH8UO25aNM181K_gloQ | preprocess_params | testuser1 |
Track functions¶
If you want more-fined-grained data lineage tracking, use the tracked() decorator.
In a notebook¶
ln.Feature(name="subset_rows", dtype="int").save() # define parameters
ln.Feature(name="subset_cols", dtype="int").save()
ln.Feature(name="input_artifact_key", dtype="str").save()
ln.Feature(name="output_artifact_key", dtype="str").save()
Feature(uid='sO8Jw4zAQXSS', name='output_artifact_key', dtype='str', array_rank=0, array_size=0, branch_id=1, space_id=1, created_by_id=1, run_id=1, created_at=2025-06-12 17:22:17 UTC)
Define a function and decorate it with tracked():
@ln.tracked()
def subset_dataframe(
input_artifact_key: str,
output_artifact_key: str,
subset_rows: int = 2,
subset_cols: int = 2,
) -> None:
artifact = ln.Artifact.get(key=input_artifact_key)
dataset = artifact.load()
new_data = dataset.iloc[:subset_rows, :subset_cols]
ln.Artifact.from_df(new_data, key=output_artifact_key).save()
Prepare a test dataset:
df = ln.core.datasets.small_dataset1(otype="DataFrame")
input_artifact_key = "my_analysis/dataset.parquet"
artifact = ln.Artifact.from_df(df, key=input_artifact_key).save()
Run the function with default params:
ouput_artifact_key = input_artifact_key.replace(".parquet", "_subsetted.parquet")
subset_dataframe(input_artifact_key, ouput_artifact_key)
Query for the output:
subsetted_artifact = ln.Artifact.get(key=ouput_artifact_key)
subsetted_artifact.view_lineage()

This is the run that created the subsetted_artifact:
subsetted_artifact.run
Run(uid='BWZExB6MkHglvnzd', started_at=2025-06-12 17:22:17 UTC, finished_at=2025-06-12 17:22:17 UTC, branch_id=1, space_id=1, transform_id=3, created_by_id=1, initiated_by_run_id=1, created_at=2025-06-12 17:22:17 UTC)
This is the function that created it:
subsetted_artifact.run.transform
Transform(uid='iPmZXRPOsIZ30000', is_latest=True, key='track.ipynb/subset_dataframe.py', type='function', hash='F_wwrfFs6zmzMGVilG2Prg', branch_id=1, space_id=1, created_by_id=1, created_at=2025-06-12 17:22:17 UTC)
This is the source code of this function:
subsetted_artifact.run.transform.source_code
'@ln.tracked()\ndef subset_dataframe(\n input_artifact_key: str,\n output_artifact_key: str,\n subset_rows: int = 2,\n subset_cols: int = 2,\n) -> None:\n artifact = ln.Artifact.get(key=input_artifact_key)\n dataset = artifact.load()\n new_data = dataset.iloc[:subset_rows, :subset_cols]\n ln.Artifact.from_df(new_data, key=output_artifact_key).save()\n'
These are all versions of this function:
subsetted_artifact.run.transform.versions.df()
| uid | key | description | type | source_code | hash | reference | reference_type | space_id | _template_id | version | is_latest | created_at | created_by_id | _aux | branch_id | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| id | ||||||||||||||||
| 3 | iPmZXRPOsIZ30000 | track.ipynb/subset_dataframe.py | None | function | @ln.tracked()\ndef subset_dataframe(\n inpu... | F_wwrfFs6zmzMGVilG2Prg | None | None | 1 | None | None | True | 2025-06-12 17:22:17.587000+00:00 | 1 | None | 1 |
This is the initating run that triggered the function call:
subsetted_artifact.run.initiated_by_run
Run(uid='yuDyaffWo5cC9y3t', started_at=2025-06-12 17:22:09 UTC, branch_id=1, space_id=1, transform_id=1, created_by_id=1, created_at=2025-06-12 17:22:09 UTC)
This is the transform of the initiating run:
subsetted_artifact.run.initiated_by_run.transform
Transform(uid='d3LEY4x5ZnlF0000', is_latest=True, key='track.ipynb', description='Track notebooks, scripts & functions', type='notebook', branch_id=1, space_id=1, created_by_id=1, created_at=2025-06-12 17:22:09 UTC)
These are the parameters of the run:
subsetted_artifact.run.features.get_values()
{'input_artifact_key': 'my_analysis/dataset.parquet',
'output_artifact_key': 'my_analysis/dataset_subsetted.parquet',
'subset_cols': 2,
'subset_rows': 2}
These input artifacts:
subsetted_artifact.run.input_artifacts.df()
| uid | key | description | suffix | kind | otype | size | hash | n_files | n_observations | _hash_type | _key_is_virtual | _overwrite_versions | space_id | storage_id | schema_id | version | is_latest | run_id | created_at | created_by_id | _aux | branch_id | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| id | |||||||||||||||||||||||
| 4 | Uq1Su0GSE1pSFvF70000 | my_analysis/dataset.parquet | None | .parquet | dataset | DataFrame | 9868 | 8-_BZRWEGUQzd8T8U2DCsA | None | 3 | md5 | True | False | 1 | 1 | None | None | True | 1 | 2025-06-12 17:22:17.564000+00:00 | 1 | None | 1 |
These are output artifacts:
subsetted_artifact.run.output_artifacts.df()
| uid | key | description | suffix | kind | otype | size | hash | n_files | n_observations | _hash_type | _key_is_virtual | _overwrite_versions | space_id | storage_id | schema_id | version | is_latest | run_id | created_at | created_by_id | _aux | branch_id | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| id | |||||||||||||||||||||||
| 5 | 4j2MsfuOrObuj4ry0000 | my_analysis/dataset_subsetted.parquet | None | .parquet | dataset | DataFrame | 3238 | qyOwv-ZalTsQ3ba7phCLkg | None | 2 | md5 | True | False | 1 | 1 | None | None | True | 3 | 2025-06-12 17:22:17.646000+00:00 | 1 | None | 1 |
Re-run the function with a different parameter:
subsetted_artifact = subset_dataframe(
input_artifact_key, ouput_artifact_key, subset_cols=3
)
subsetted_artifact = ln.Artifact.get(key=ouput_artifact_key)
subsetted_artifact.view_lineage()
Show code cell output
→ creating new artifact version for key='my_analysis/dataset_subsetted.parquet' (storage: '/home/runner/work/lamindb/lamindb/docs/test-track')

We created a new run:
subsetted_artifact.run
Run(uid='WOVHsURSdZuTj3uF', started_at=2025-06-12 17:22:18 UTC, finished_at=2025-06-12 17:22:18 UTC, branch_id=1, space_id=1, transform_id=3, created_by_id=1, initiated_by_run_id=1, created_at=2025-06-12 17:22:18 UTC)
With new parameters:
subsetted_artifact.run.features.get_values()
{'input_artifact_key': 'my_analysis/dataset.parquet',
'output_artifact_key': 'my_analysis/dataset_subsetted.parquet',
'subset_cols': 3,
'subset_rows': 2}
And a new version of the output artifact:
subsetted_artifact.run.output_artifacts.df()
| uid | key | description | suffix | kind | otype | size | hash | n_files | n_observations | _hash_type | _key_is_virtual | _overwrite_versions | space_id | storage_id | schema_id | version | is_latest | run_id | created_at | created_by_id | _aux | branch_id | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| id | |||||||||||||||||||||||
| 6 | 4j2MsfuOrObuj4ry0001 | my_analysis/dataset_subsetted.parquet | None | .parquet | dataset | DataFrame | 3852 | t7OPyiQSIk2_01X7zZxvrA | None | 2 | md5 | True | False | 1 | 1 | None | None | True | 4 | 2025-06-12 17:22:18.150000+00:00 | 1 | None | 1 |
See the state of the database:
ln.view()
Show code cell output
Artifact
| uid | key | description | suffix | kind | otype | size | hash | n_files | n_observations | _hash_type | _key_is_virtual | _overwrite_versions | space_id | storage_id | schema_id | version | is_latest | run_id | created_at | created_by_id | _aux | branch_id | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| id | |||||||||||||||||||||||
| 6 | 4j2MsfuOrObuj4ry0001 | my_analysis/dataset_subsetted.parquet | None | .parquet | dataset | DataFrame | 3852 | t7OPyiQSIk2_01X7zZxvrA | None | 2.0 | md5 | True | False | 1 | 1 | None | None | True | 4 | 2025-06-12 17:22:18.150000+00:00 | 1 | None | 1 |
| 5 | 4j2MsfuOrObuj4ry0000 | my_analysis/dataset_subsetted.parquet | None | .parquet | dataset | DataFrame | 3238 | qyOwv-ZalTsQ3ba7phCLkg | None | 2.0 | md5 | True | False | 1 | 1 | None | None | False | 3 | 2025-06-12 17:22:17.646000+00:00 | 1 | None | 1 |
| 4 | Uq1Su0GSE1pSFvF70000 | my_analysis/dataset.parquet | None | .parquet | dataset | DataFrame | 9868 | 8-_BZRWEGUQzd8T8U2DCsA | None | 3.0 | md5 | True | False | 1 | 1 | None | None | True | 1 | 2025-06-12 17:22:17.564000+00:00 | 1 | None | 1 |
| 1 | gPAQMHTfl9M4T4sW0000 | my_file.fcs | None | .fcs | None | None | 19330507 | rCPvmZB19xs4zHZ7p_-Wrg | None | NaN | md5 | True | False | 1 | 1 | None | None | True | 1 | 2025-06-12 17:22:12.198000+00:00 | 1 | None | 1 |
Feature
| uid | name | dtype | is_type | unit | description | array_rank | array_size | array_shape | proxy_dtype | synonyms | _expect_many | _curation | space_id | type_id | run_id | created_at | created_by_id | _aux | branch_id | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| id | ||||||||||||||||||||
| 7 | sO8Jw4zAQXSS | output_artifact_key | str | None | None | None | 0 | 0 | None | None | None | None | None | 1 | None | 1 | 2025-06-12 17:22:17.505000+00:00 | 1 | {'af': {'0': None, '1': True, '2': False}} | 1 |
| 6 | MoPipv4cUzHK | input_artifact_key | str | None | None | None | 0 | 0 | None | None | None | None | None | 1 | None | 1 | 2025-06-12 17:22:17.494000+00:00 | 1 | {'af': {'0': None, '1': True, '2': False}} | 1 |
| 5 | khFTRp8CDxDr | subset_cols | int | None | None | None | 0 | 0 | None | None | None | None | None | 1 | None | 1 | 2025-06-12 17:22:17.484000+00:00 | 1 | {'af': {'0': None, '1': True, '2': False}} | 1 |
| 4 | SlN5g9Kwdzpr | subset_rows | int | None | None | None | 0 | 0 | None | None | None | None | None | 1 | None | 1 | 2025-06-12 17:22:17.474000+00:00 | 1 | {'af': {'0': None, '1': True, '2': False}} | 1 |
| 3 | O9lX1wOZa7Ng | preprocess_params | dict | None | None | None | 0 | 0 | None | None | None | None | None | 1 | None | 1 | 2025-06-12 17:22:12.431000+00:00 | 1 | {'af': {'0': None, '1': True, '2': False}} | 1 |
| 2 | RdRhyRw0VJW4 | learning_rate | float | None | None | None | 0 | 0 | None | None | None | None | None | 1 | None | 1 | 2025-06-12 17:22:12.422000+00:00 | 1 | {'af': {'0': None, '1': True, '2': False}} | 1 |
| 1 | fqU9YqMocyfL | input_dir | str | None | None | None | 0 | 0 | None | None | None | None | None | 1 | None | 1 | 2025-06-12 17:22:12.360000+00:00 | 1 | {'af': {'0': None, '1': True, '2': False}} | 1 |
FeatureValue
| value | hash | space_id | feature_id | run_id | created_at | created_by_id | _aux | branch_id | |
|---|---|---|---|---|---|---|---|---|---|
| id | |||||||||
| 1 | ./mydataset | 71I4KdtOlqWZYoR9KaVTvw | 1 | 1 | NaN | 2025-06-12 17:22:15.196000+00:00 | 1 | None | 1 |
| 2 | 0.01 | BIF-_RHBU2Sm7COXgAOIYg | 1 | 2 | NaN | 2025-06-12 17:22:15.198000+00:00 | 1 | None | 1 |
| 3 | {'downsample': True, 'normalization': 'the_goo... | 4ehQH8UO25aNM181K_gloQ | 1 | 3 | NaN | 2025-06-12 17:22:15.201000+00:00 | 1 | None | 1 |
| 4 | 2 | yB5yjZ1ML2NvBn-JzBSGLA | 1 | 4 | 1.0 | 2025-06-12 17:22:17.612000+00:00 | 1 | None | 1 |
| 5 | 2 | yB5yjZ1ML2NvBn-JzBSGLA | 1 | 5 | 1.0 | 2025-06-12 17:22:17.615000+00:00 | 1 | None | 1 |
| 6 | my_analysis/dataset.parquet | 1ImgyYl4KlCl3XCd-aQE9Q | 1 | 6 | 1.0 | 2025-06-12 17:22:17.617000+00:00 | 1 | None | 1 |
| 7 | my_analysis/dataset_subsetted.parquet | G9luXJ51Hi4-Csrifos0Lw | 1 | 7 | 1.0 | 2025-06-12 17:22:17.619000+00:00 | 1 | None | 1 |
Project
| uid | name | is_type | abbr | url | start_date | end_date | _status_code | space_id | type_id | run_id | created_at | created_by_id | _aux | branch_id | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| id | |||||||||||||||
| 1 | CQAmaupZrzlu | My project | False | None | None | None | None | 0 | 1 | None | None | 2025-06-12 17:22:08.566000+00:00 | 1 | None | 1 |
Run
| uid | name | started_at | finished_at | reference | reference_type | _is_consecutive | _status_code | space_id | transform_id | report_id | _logfile_id | environment_id | initiated_by_run_id | created_at | created_by_id | _aux | branch_id | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| id | ||||||||||||||||||
| 1 | yuDyaffWo5cC9y3t | None | 2025-06-12 17:22:09.711478+00:00 | NaT | None | None | None | 0 | 1 | 1 | NaN | None | NaN | NaN | 2025-06-12 17:22:09.712000+00:00 | 1 | None | 1 |
| 2 | iTteMw5u6iMX8PVz | None | 2025-06-12 17:22:15.173342+00:00 | 2025-06-12 17:22:16.920746+00:00 | None | None | True | 0 | 1 | 2 | 3.0 | None | 2.0 | NaN | 2025-06-12 17:22:15.174000+00:00 | 1 | None | 1 |
| 3 | BWZExB6MkHglvnzd | None | 2025-06-12 17:22:17.592514+00:00 | 2025-06-12 17:22:17.652317+00:00 | None | None | None | 0 | 1 | 3 | NaN | None | NaN | 1.0 | 2025-06-12 17:22:17.593000+00:00 | 1 | None | 1 |
| 4 | WOVHsURSdZuTj3uF | None | 2025-06-12 17:22:18.097250+00:00 | 2025-06-12 17:22:18.156697+00:00 | None | None | None | 0 | 1 | 3 | NaN | None | NaN | 1.0 | 2025-06-12 17:22:18.097000+00:00 | 1 | None | 1 |
Storage
| uid | root | description | type | region | instance_uid | space_id | run_id | created_at | created_by_id | _aux | branch_id | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| id | ||||||||||||
| 1 | SD3eZ5q7nCmU | /home/runner/work/lamindb/lamindb/docs/test-track | None | local | None | 73KPGC58ahU9 | 1 | None | 2025-06-12 17:22:05.071000+00:00 | 1 | None | 1 |
Transform
| uid | key | description | type | source_code | hash | reference | reference_type | space_id | _template_id | version | is_latest | created_at | created_by_id | _aux | branch_id | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| id | ||||||||||||||||
| 3 | iPmZXRPOsIZ30000 | track.ipynb/subset_dataframe.py | None | function | @ln.tracked()\ndef subset_dataframe(\n inpu... | F_wwrfFs6zmzMGVilG2Prg | None | None | 1 | None | None | True | 2025-06-12 17:22:17.587000+00:00 | 1 | None | 1 |
| 2 | YFQL4ZZuRI6R0000 | run_track_with_params.py | run_track_with_params.py | script | import argparse\nimport lamindb as ln\n\nif __... | nRUs3ZjuVTbKtBmSXpVQ5A | None | None | 1 | None | None | True | 2025-06-12 17:22:15.170000+00:00 | 1 | None | 1 |
| 1 | d3LEY4x5ZnlF0000 | track.ipynb | Track notebooks, scripts & functions | notebook | None | None | None | None | 1 | None | None | True | 2025-06-12 17:22:09.699000+00:00 | 1 | None | 1 |
In a script¶
import argparse
import lamindb as ln
ln.Param(name="run_workflow_subset", dtype=bool).save()
@ln.tracked()
def subset_dataframe(
artifact: ln.Artifact,
subset_rows: int = 2,
subset_cols: int = 2,
run: ln.Run | None = None,
) -> ln.Artifact:
dataset = artifact.load(is_run_input=run)
new_data = dataset.iloc[:subset_rows, :subset_cols]
new_key = artifact.key.replace(".parquet", "_subsetted.parquet")
return ln.Artifact.from_df(new_data, key=new_key, run=run).save()
if __name__ == "__main__":
p = argparse.ArgumentParser()
p.add_argument("--subset", action="store_true")
args = p.parse_args()
params = {"run_workflow_subset": args.subset}
ln.track(params=params)
if args.subset:
df = ln.core.datasets.small_dataset1(otype="DataFrame")
artifact = ln.Artifact.from_df(df, key="my_analysis/dataset.parquet").save()
subsetted_artifact = subset_dataframe(artifact)
ln.finish()
!python scripts/run_workflow.py --subset
Show code cell output
→ connected lamindb: testuser1/test-track
→ created Transform('a4AOWnnS7uDT0000'), started new Run('MLPIy8ld...') at 2025-06-12 17:22:21 UTC
→ params: run_workflow_subset=True
• recommendation: to identify the script across renames, pass the uid: ln.track("a4AOWnnS7uDT", params={...})
→ returning existing artifact with same hash: Artifact(uid='Uq1Su0GSE1pSFvF70000', is_latest=True, key='my_analysis/dataset.parquet', suffix='.parquet', kind='dataset', otype='DataFrame', size=9868, hash='8-_BZRWEGUQzd8T8U2DCsA', n_observations=3, branch_id=1, space_id=1, storage_id=1, run_id=1, created_by_id=1, created_at=2025-06-12 17:22:17 UTC); to track this artifact as an input, use: ln.Artifact.get()
→ returning existing artifact with same hash: Artifact(uid='4j2MsfuOrObuj4ry0001', is_latest=True, key='my_analysis/dataset_subsetted.parquet', suffix='.parquet', kind='dataset', otype='DataFrame', size=3852, hash='t7OPyiQSIk2_01X7zZxvrA', n_observations=2, branch_id=1, space_id=1, storage_id=1, run_id=4, created_by_id=1, created_at=2025-06-12 17:22:18 UTC); to track this artifact as an input, use: ln.Artifact.get()
→ returning existing artifact with same hash: Artifact(uid='WydfXCcxdE2yJBM80000', is_latest=True, description='log streams of run iTteMw5u6iMX8PVz', suffix='.txt', kind='__lamindb_run__', size=0, hash='1B2M2Y8AsgTpgAmY7PhCfg', branch_id=1, space_id=1, storage_id=1, created_by_id=1, created_at=2025-06-12 17:22:16 UTC); to track this artifact as an input, use: ln.Artifact.get()
! updated description from log streams of run iTteMw5u6iMX8PVz to log streams of run MLPIy8ld73fySdDN
→ finished Run('MLPIy8ld') after 1s at 2025-06-12 17:22:22 UTC
ln.view()
Show code cell output
Artifact
| uid | key | description | suffix | kind | otype | size | hash | n_files | n_observations | _hash_type | _key_is_virtual | _overwrite_versions | space_id | storage_id | schema_id | version | is_latest | run_id | created_at | created_by_id | _aux | branch_id | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| id | |||||||||||||||||||||||
| 6 | 4j2MsfuOrObuj4ry0001 | my_analysis/dataset_subsetted.parquet | None | .parquet | dataset | DataFrame | 3852 | t7OPyiQSIk2_01X7zZxvrA | None | 2.0 | md5 | True | False | 1 | 1 | None | None | True | 4 | 2025-06-12 17:22:18.150000+00:00 | 1 | None | 1 |
| 5 | 4j2MsfuOrObuj4ry0000 | my_analysis/dataset_subsetted.parquet | None | .parquet | dataset | DataFrame | 3238 | qyOwv-ZalTsQ3ba7phCLkg | None | 2.0 | md5 | True | False | 1 | 1 | None | None | False | 3 | 2025-06-12 17:22:17.646000+00:00 | 1 | None | 1 |
| 4 | Uq1Su0GSE1pSFvF70000 | my_analysis/dataset.parquet | None | .parquet | dataset | DataFrame | 9868 | 8-_BZRWEGUQzd8T8U2DCsA | None | 3.0 | md5 | True | False | 1 | 1 | None | None | True | 1 | 2025-06-12 17:22:17.564000+00:00 | 1 | None | 1 |
| 1 | gPAQMHTfl9M4T4sW0000 | my_file.fcs | None | .fcs | None | None | 19330507 | rCPvmZB19xs4zHZ7p_-Wrg | None | NaN | md5 | True | False | 1 | 1 | None | None | True | 1 | 2025-06-12 17:22:12.198000+00:00 | 1 | None | 1 |
Feature
| uid | name | dtype | is_type | unit | description | array_rank | array_size | array_shape | proxy_dtype | synonyms | _expect_many | _curation | space_id | type_id | run_id | created_at | created_by_id | _aux | branch_id | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| id | ||||||||||||||||||||
| 8 | SzBL54VnpxRD | run_workflow_subset | bool | None | None | None | 0 | 0 | None | None | None | None | None | 1 | None | NaN | 2025-06-12 17:22:21.253000+00:00 | 1 | {'af': {'0': None, '1': True, '2': False}} | 1 |
| 7 | sO8Jw4zAQXSS | output_artifact_key | str | None | None | None | 0 | 0 | None | None | None | None | None | 1 | None | 1.0 | 2025-06-12 17:22:17.505000+00:00 | 1 | {'af': {'0': None, '1': True, '2': False}} | 1 |
| 6 | MoPipv4cUzHK | input_artifact_key | str | None | None | None | 0 | 0 | None | None | None | None | None | 1 | None | 1.0 | 2025-06-12 17:22:17.494000+00:00 | 1 | {'af': {'0': None, '1': True, '2': False}} | 1 |
| 5 | khFTRp8CDxDr | subset_cols | int | None | None | None | 0 | 0 | None | None | None | None | None | 1 | None | 1.0 | 2025-06-12 17:22:17.484000+00:00 | 1 | {'af': {'0': None, '1': True, '2': False}} | 1 |
| 4 | SlN5g9Kwdzpr | subset_rows | int | None | None | None | 0 | 0 | None | None | None | None | None | 1 | None | 1.0 | 2025-06-12 17:22:17.474000+00:00 | 1 | {'af': {'0': None, '1': True, '2': False}} | 1 |
| 3 | O9lX1wOZa7Ng | preprocess_params | dict | None | None | None | 0 | 0 | None | None | None | None | None | 1 | None | 1.0 | 2025-06-12 17:22:12.431000+00:00 | 1 | {'af': {'0': None, '1': True, '2': False}} | 1 |
| 2 | RdRhyRw0VJW4 | learning_rate | float | None | None | None | 0 | 0 | None | None | None | None | None | 1 | None | 1.0 | 2025-06-12 17:22:12.422000+00:00 | 1 | {'af': {'0': None, '1': True, '2': False}} | 1 |
FeatureValue
| value | hash | space_id | feature_id | run_id | created_at | created_by_id | _aux | branch_id | |
|---|---|---|---|---|---|---|---|---|---|
| id | |||||||||
| 1 | ./mydataset | 71I4KdtOlqWZYoR9KaVTvw | 1 | 1 | NaN | 2025-06-12 17:22:15.196000+00:00 | 1 | None | 1 |
| 2 | 0.01 | BIF-_RHBU2Sm7COXgAOIYg | 1 | 2 | NaN | 2025-06-12 17:22:15.198000+00:00 | 1 | None | 1 |
| 3 | {'downsample': True, 'normalization': 'the_goo... | 4ehQH8UO25aNM181K_gloQ | 1 | 3 | NaN | 2025-06-12 17:22:15.201000+00:00 | 1 | None | 1 |
| 4 | 2 | yB5yjZ1ML2NvBn-JzBSGLA | 1 | 4 | 1.0 | 2025-06-12 17:22:17.612000+00:00 | 1 | None | 1 |
| 5 | 2 | yB5yjZ1ML2NvBn-JzBSGLA | 1 | 5 | 1.0 | 2025-06-12 17:22:17.615000+00:00 | 1 | None | 1 |
| 6 | my_analysis/dataset.parquet | 1ImgyYl4KlCl3XCd-aQE9Q | 1 | 6 | 1.0 | 2025-06-12 17:22:17.617000+00:00 | 1 | None | 1 |
| 7 | my_analysis/dataset_subsetted.parquet | G9luXJ51Hi4-Csrifos0Lw | 1 | 7 | 1.0 | 2025-06-12 17:22:17.619000+00:00 | 1 | None | 1 |
Project
| uid | name | is_type | abbr | url | start_date | end_date | _status_code | space_id | type_id | run_id | created_at | created_by_id | _aux | branch_id | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| id | |||||||||||||||
| 1 | CQAmaupZrzlu | My project | False | None | None | None | None | 0 | 1 | None | None | 2025-06-12 17:22:08.566000+00:00 | 1 | None | 1 |
Run
| uid | name | started_at | finished_at | reference | reference_type | _is_consecutive | _status_code | space_id | transform_id | report_id | _logfile_id | environment_id | initiated_by_run_id | created_at | created_by_id | _aux | branch_id | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| id | ||||||||||||||||||
| 1 | yuDyaffWo5cC9y3t | None | 2025-06-12 17:22:09.711478+00:00 | NaT | None | None | None | 0 | 1 | 1 | NaN | None | NaN | NaN | 2025-06-12 17:22:09.712000+00:00 | 1 | None | 1 |
| 2 | iTteMw5u6iMX8PVz | None | 2025-06-12 17:22:15.173342+00:00 | 2025-06-12 17:22:16.920746+00:00 | None | None | True | 0 | 1 | 2 | 3.0 | None | 2.0 | NaN | 2025-06-12 17:22:15.174000+00:00 | 1 | None | 1 |
| 3 | BWZExB6MkHglvnzd | None | 2025-06-12 17:22:17.592514+00:00 | 2025-06-12 17:22:17.652317+00:00 | None | None | None | 0 | 1 | 3 | NaN | None | NaN | 1.0 | 2025-06-12 17:22:17.593000+00:00 | 1 | None | 1 |
| 4 | WOVHsURSdZuTj3uF | None | 2025-06-12 17:22:18.097250+00:00 | 2025-06-12 17:22:18.156697+00:00 | None | None | None | 0 | 1 | 3 | NaN | None | NaN | 1.0 | 2025-06-12 17:22:18.097000+00:00 | 1 | None | 1 |
| 5 | MLPIy8ld73fySdDN | None | 2025-06-12 17:22:21.268684+00:00 | 2025-06-12 17:22:22.277568+00:00 | None | None | True | 0 | 1 | 4 | 3.0 | None | 2.0 | NaN | 2025-06-12 17:22:21.269000+00:00 | 1 | None | 1 |
| 6 | Cl5r34gOWwdjUqFV | None | 2025-06-12 17:22:22.222125+00:00 | 2025-06-12 17:22:22.272374+00:00 | None | None | None | 0 | 1 | 5 | NaN | None | NaN | 5.0 | 2025-06-12 17:22:22.222000+00:00 | 1 | None | 1 |
Storage
| uid | root | description | type | region | instance_uid | space_id | run_id | created_at | created_by_id | _aux | branch_id | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| id | ||||||||||||
| 1 | SD3eZ5q7nCmU | /home/runner/work/lamindb/lamindb/docs/test-track | None | local | None | 73KPGC58ahU9 | 1 | None | 2025-06-12 17:22:05.071000+00:00 | 1 | None | 1 |
Transform
| uid | key | description | type | source_code | hash | reference | reference_type | space_id | _template_id | version | is_latest | created_at | created_by_id | _aux | branch_id | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| id | ||||||||||||||||
| 5 | fwic6jM3dv3A0000 | run_workflow.py/subset_dataframe.py | None | function | @ln.tracked()\ndef subset_dataframe(\n arti... | Dqbr_hMfHs17EhbPXP_PyQ | None | None | 1 | None | None | True | 2025-06-12 17:22:22.220000+00:00 | 1 | None | 1 |
| 4 | a4AOWnnS7uDT0000 | run_workflow.py | run_workflow.py | script | import argparse\nimport lamindb as ln\n\nln.Pa... | yqr8j5hTUulVRzv4J-o9SQ | None | None | 1 | None | None | True | 2025-06-12 17:22:21.266000+00:00 | 1 | None | 1 |
| 3 | iPmZXRPOsIZ30000 | track.ipynb/subset_dataframe.py | None | function | @ln.tracked()\ndef subset_dataframe(\n inpu... | F_wwrfFs6zmzMGVilG2Prg | None | None | 1 | None | None | True | 2025-06-12 17:22:17.587000+00:00 | 1 | None | 1 |
| 2 | YFQL4ZZuRI6R0000 | run_track_with_params.py | run_track_with_params.py | script | import argparse\nimport lamindb as ln\n\nif __... | nRUs3ZjuVTbKtBmSXpVQ5A | None | None | 1 | None | None | True | 2025-06-12 17:22:15.170000+00:00 | 1 | None | 1 |
| 1 | d3LEY4x5ZnlF0000 | track.ipynb | Track notebooks, scripts & functions | notebook | None | None | None | None | 1 | None | None | True | 2025-06-12 17:22:09.699000+00:00 | 1 | None | 1 |
Sync scripts with git¶
To sync with your git commit, add the following line to your script:
ln.settings.sync_git_repo = <YOUR-GIT-REPO-URL>
import lamindb as ln
ln.settings.sync_git_repo = "https://github.com/..."
ln.track()
# your code
ln.finish()
You’ll now see the GitHub emoji clickable on the hub.
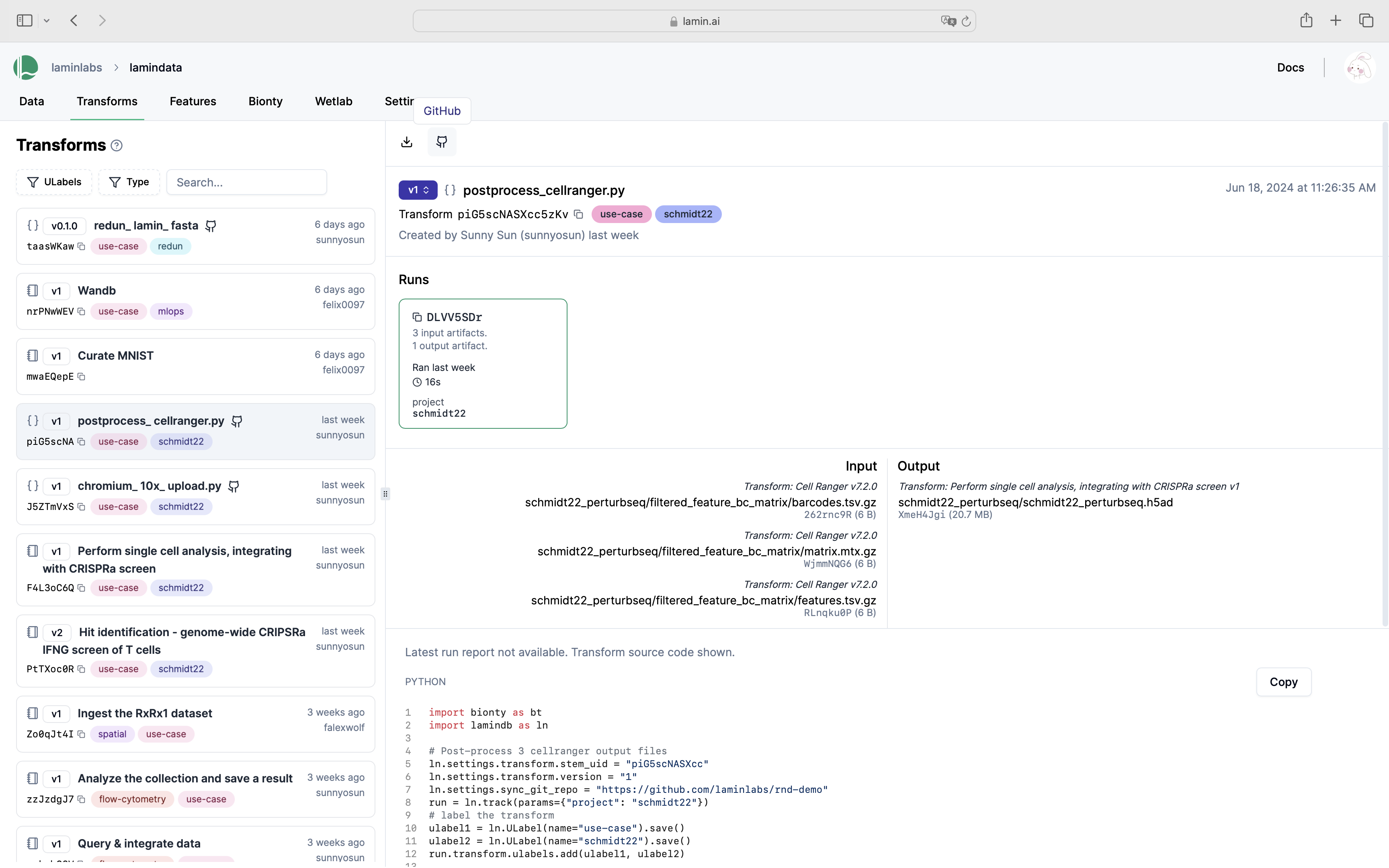
Manage notebook templates¶
A notebook acts like a template upon using lamin load to load it. Consider you run:
lamin load https://lamin.ai/account/instance/transform/Akd7gx7Y9oVO0000
Upon running the returned notebook, you’ll automatically create a new version and be able to browse it via the version dropdown on the UI.
Additionally, you can:
label using
ULabel, e.g.,transform.ulabels.add(template_label)tag with an indicative
versionstring, e.g.,transform.version = "T1"; transform.save()
Saving a notebook as an artifact
Sometimes you might want to save a notebook as an artifact. This is how you can do it:
lamin save template1.ipynb --key templates/template1.ipynb --description "Template for analysis type 1" --registry artifact
Show code cell content
assert run.features.get_values() == {
"input_dir": "./mydataset",
"learning_rate": 0.01,
"preprocess_params": {"downsample": True, "normalization": "the_good_one"},
}
assert my_project.artifacts.exists()
assert my_project.transforms.exists()
assert my_project.runs.exists()
# clean up test instance
!rm -r ./test-track
!lamin delete --force test-track
• deleting instance testuser1/test-track